

HIV Case-Based Surveillance
0.2.0 - CI Build
![]()
HIV Case-Based Surveillance
0.2.0 - CI Build
![]()
HIV Case-Based Surveillance, published by Jembi Health Systems. This is not an authorized publication; it is the continuous build for version 0.2.0). This version is based on the current content of https://github.com/openhie/HIV-CBS and changes regularly. See the Directory of published versions
Testing data for accuracy and correctness is essential for any business who relies on quality data for the purpose of decision making. This is even more critical in healthcare as data is very commonly used to monitor the health status of a client and used to make decisions in regards to diagnosis and treatment plans etc.
For this reason, using an established automated testing framework can be highly beneficial to ensure data quality.
In the context of DISI's reference platform architecture, a Central Data Repository (CDR) Testing Framework has been developed as the testing tool to support quality assurance, end-to-end.
The CDR testing framework is a custom developed package developed by Jembi Health Systems that sits on top of Cucumber and Gherkin's automation engine.
For more information in regards to the setup, deployment & use of the CDR testing framework, please consult the Developer & Tester Guide.
The following sections offer a brief overview and background into what an automated testing framework can look like to support data quality in health systems.
Tests can be carried out in the following ways.
- The CDR testing framework operates on a transactional basis meaning that bulk submissions to the CDR are not possible.
The Central Data Repository (CDR) Testing Framework is an automation tool designed to assist with report data accuracy as well as test the data pipeline end-to-end.
The CDR testing framework is built on top of Cucumber, which is a general automation testing framework but also comes packaged with more specific custom developed modules which are used to query input and expected outcome datasets to assist with the measurement of data quality in the analytics platform.
The CDR testing framework implements a modular design which will enable analysts, testers and developers to quite easily build new report modules to efficiently execute on-demand and regression testing processes against the data pipeline.
The illustration depicted as a High-level Design Architecture offers an overview of what the CDR testing framework modules should look like.
The illustration depicted as a Component Architecture is an example of what the type of components could look like to support end-to-end testing.
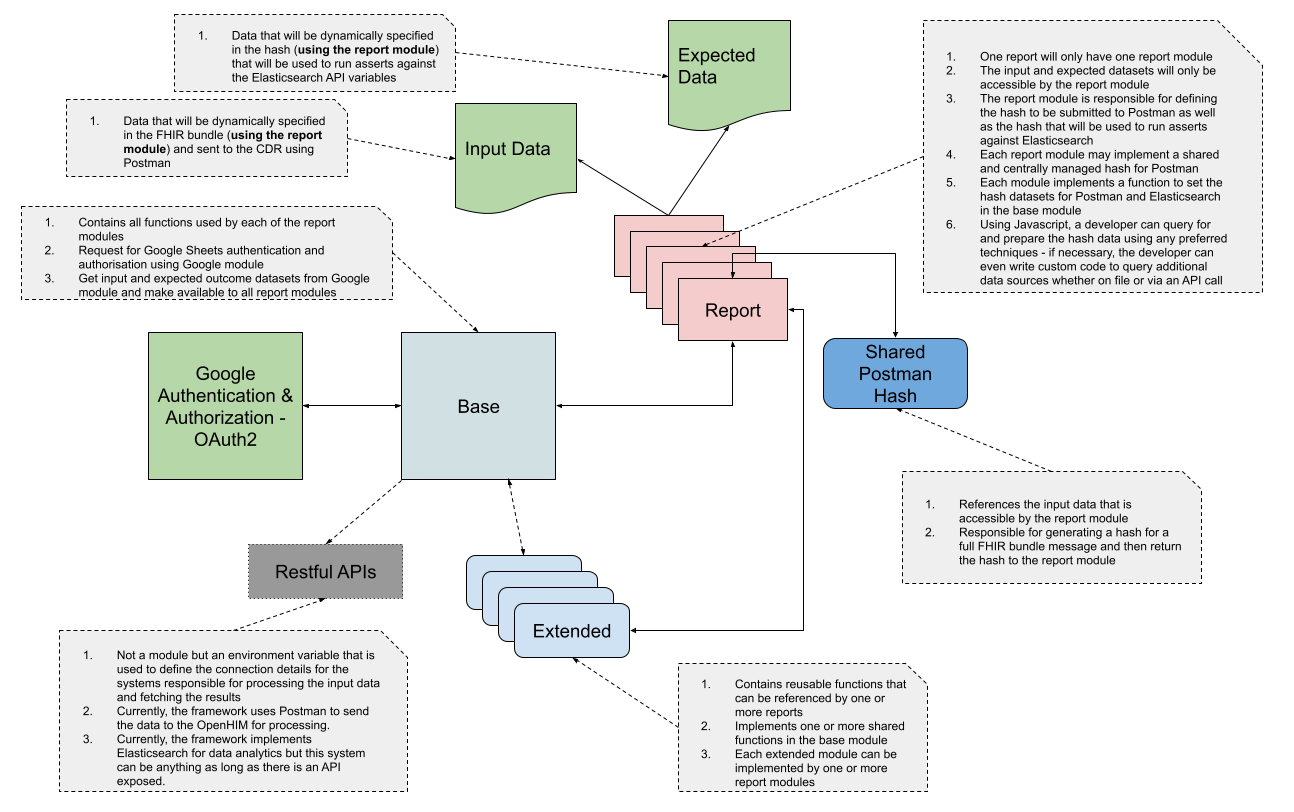
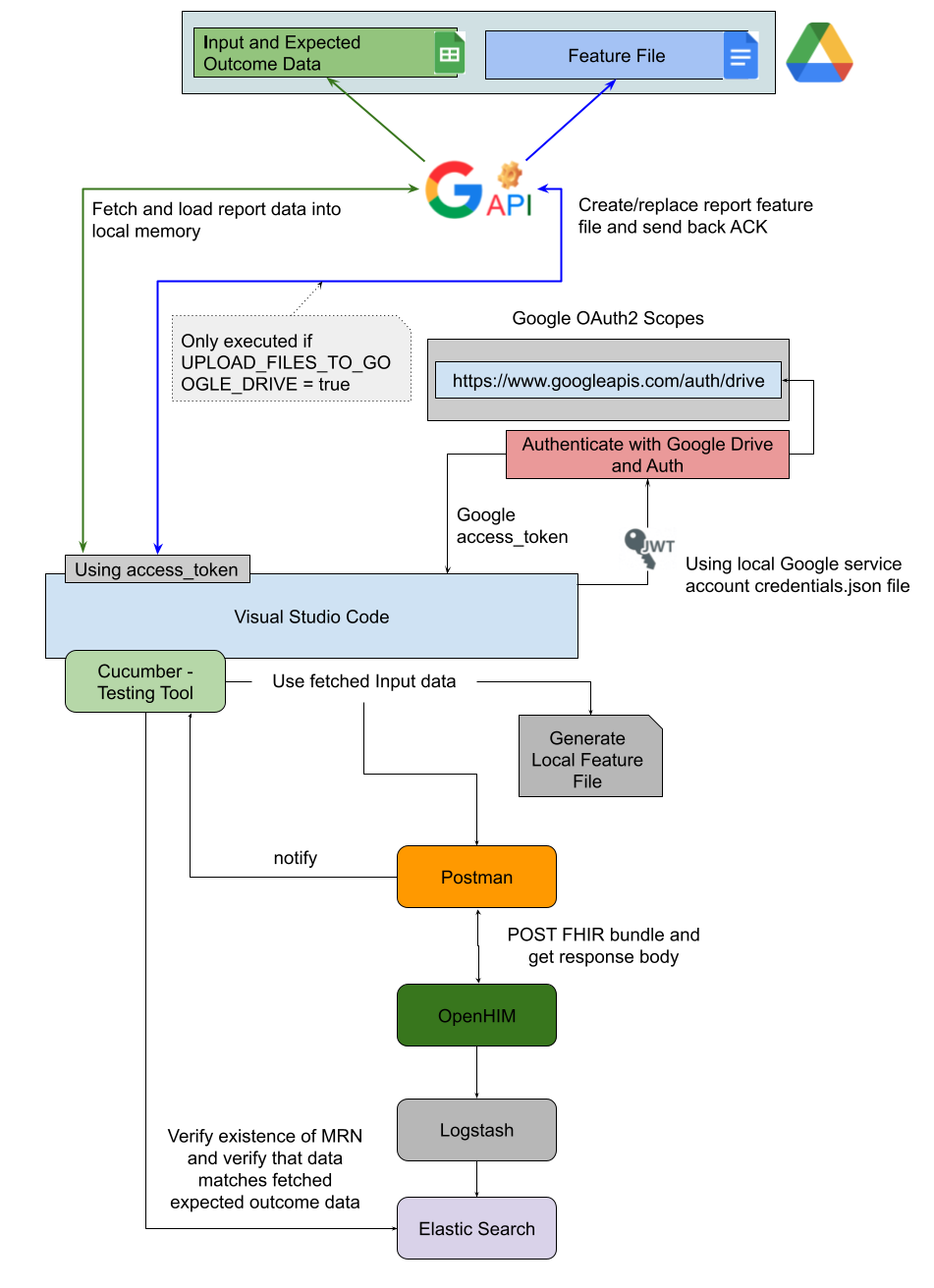
In order for the CDR Testing Framework to be considered successful in terms of end-to-end automation testing, the framework must be able to not only submit input test data to the CDR using Postman but also be able to query the analytics platform to verify whether the input data that was submitted was also successfully flattened and stored by the analytics platform.
Furthermore, the framework must also be able to check each and every element of the patient record to ensure that the value that is stored matches the documented expected outcome data for the patient.
For the purpose of streamlined data management activities, the input and expected outcome datasets can be centrally hosted as Google Sheets.
The CDR Testing Framework should then fetch data from both datasets and use it during data assertions.
Input Data
This is the set of data that will be submitted to the CDR to mimic events at a given facility. The input dataset must be defined using static data to ensure that the expected outcome data values marry up with what was submitted to the CDR.
Expected Outcome Data
This is the set of data that will govern the quality and correctness of data at rest in the analytics platform.
In other words, the expected outcome dataset only contains patient records that must be reported on and has data values specified that correspond with the data in the input dataset and any report specification conditional logic.
The expected outcome dataset is a static and final outcome which the CDR testing framework will expect to see in the analytics platform.
If the testing framework detects a value in the analytics platform that does not correspond with the value specified for the same data element in the expected outcome dataset, the testing framework must fail that test case and immediately halt any further testing.
An expected outcome dataset may have data defined for the following types of reports.
IG © 2019+ Jembi Health Systems. Package openhie.fhir.hiv.cbs#0.2.0 based on FHIR 4.0.1. Generated 2023-04-04
Links: Table of Contents |
QA Report |
Version History |
![]() |
|